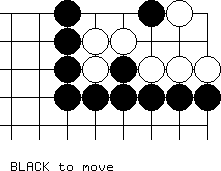
In Go, even relatively simple life and death problems can involve very arduous searches. Conceptually, if we start with a complete game tree for a given problem, various pruning and ordering techniques can be used to find a satisfactory line of play requiring less work. Some techniques are guaranteed to not change the result, and are therefore fully admissible. Others involve compromises on the accuracy of the result, and so are inadmissible, and less desirable. Some of the techniques described here are adaptations of well known methods from gaming literature; others I haven't seen described elsewhere.
This paper is only about solving well defined local problems. In actual games, local success may mean global disaster; local problems spill out and combine with one another, and small details in the resolution of one problem become key points in the next. These nasty realities are outside the scope of this paper.
The Go problems addressed in this paper have the form "status of white group, with black moving first". In descriptions of the game tree, I will use filial relationships among nodes (cousin, child, parent) in a fairly informal way; I hope it will not be difficult to follow. The examples use a negmax representation for the game tree, where all nodes are maximizers and the value of the parent is the negative of the maximum of the values of the children.
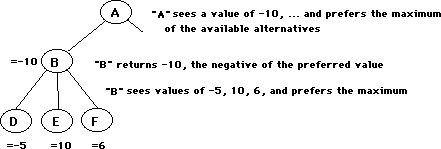
The first challenge for any problem solver is deciding when to stop, and how to evaluate each terminal node. In tsumego (life or death) problems, several natural outcomes are common. The most obvious are Black Lives, Black Dies, and Seki. It is straightforward to assign a transitive set of values to these outcomes.
Ko introduces a major complication; in effect, ko couples any local fight to the state of the game as a whole. Since the cost of winning or losing a ko depends on the state of the game as a whole, one cannot assign an absolute value to winning or losing the fight involving a ko. One can assign a relative value with fair confidence; clearly, living unconditionally is preferable to living only after winning a ko. However, considering the global situation, a different line of play might be preferable. For example, it is conceivable that the available alternatives are
It is rarely seen in practice, but under Japanese rules, no result is also a possible outcome. There is no natural ordering for this outside the context of the game as a whole. For a player firmly behind in the game, "no result" might be the most desirable outcome available. For a player needing only a few points to catch up, no result would be more desirable than a total loss, but less desirable than making a small live group. This problem solver considers "no result" to be less desirable than seki, but more desirable than losing outright.
This same kind of reasoning is also needed in a very common situation: when the search can't resolve the problem in a reasonable length of time. The depth of search in many tsumego problems is not bounded in any useful way. Any line of play that involves a possibility like "black escapes" immediately brings the entire board and the entire rest of the game into the search. Furthermore, many searches without a territorial "escape" situation never the less require excessively deep searches in some branches. In many cases, these deep searches could be avoided if the correct line of play were already known, but that would be begging the question. While searching for the correct line of play, it is easy to fall into a deep search and never get out, unless other heuristics intervene.
So, for all practical purposes, there has to be a limit on the depth of search, and this becomes an additional terminal condition that has to be evaluated along with the natural outcomes. There is no natural place in the ordering for inconclusive, except that it must be less desirable than winning outright. For example, if black is losing the game, he might prefer to escape (or continue to complicate the game) rather than form a seki and simplify it. If black were ahead, a seki might be preferable to an inconclusive result. This problem solver considers inconclusive to be equivalent to seki.
In summary, the terminal conditions for the search are the "natural" outcomes, "live" .. "live in ko" .. "seki" .. "die in ko" .. "die" into which both players have to insert a few "unnatural" outcomes according to their preferences based on the general situation.
I've chose a simple problem to illustrate the text; refer to the section titled "A practical example".
In example 1, when all potential moves are evaluated with a depth limit of 15 ply, more than 50,000 nodes are evaluated. A large number of silly lines of play are included in these 50,000.
Some "simple" heuristics could prune this tree by a large factor; for example, considering the problem to be solved when any large group is captured. The problem with such simple heuristics is that they work in some situations, but cause the correct line of play to be ignored in others. The challenge is to limit the search without losing the correct result.
First, I'll consider techniques which are guaranteed to not change the result, within the bounds established by a full width search to a specified maximum depth.
Classically, alpha-beta tree pruning is used, because it finds the same answer as a complete search, but with greatly reduced effort. The basis of alpha-beta pruning is simple; in the process of searching, remember the results that can be obtained elsewhere. When, locally, the results are good enough for one player that the other player will avoid the current line of play, then both players should avoid that line of play. In example 2, the search declines from 50,000 positions to 12,000 positions, even with a very bad initial ordering algorithm.
The effectiveness of alpha-beta is known to be very sensitive to the exact ordering of the positions evaluated, so the most obvious way to improve the its effectiveness is to improve the initial ordering. With a reasonably good ordering in example 4, alpha-beta reduces the search by another factor of 20, to about 600 positions.
Unfortunately, ordering the alternatives is a black art; any adjustments which solve one problem faster tend to make other problems solve more slowly. In the example, the correct first move is to play in the corner; any ordering that made this alternative the most likely will probably perform poorly for most other problems.
Ad-hoc techniques to improve the initial ordering, based on knowledge about go, are outside the scope of this paper. They are very important, but they are insufficient to guarantee efficient searches. The "good" ordering used by the example is based on a balance of all the factors you might expect, including liberties, eye shapes, connectivity, cutting points and so on.
or click here to see an ascii version
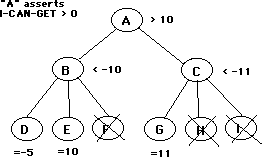
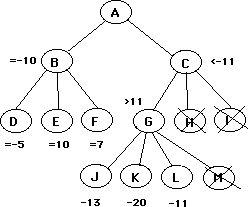
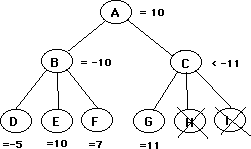
Summary: If the value to A of B is -10 and the value of G is greater than 10, then A will choose B over C, so there is no need to evaluate H and I, no matter what their values may be. The value of G has already assured that the value of C will be discarded by A.
In the process of searching with alpha-beta pruning, two parameters are derived, commonly called alpha and beta. I find it much more intuitive to call them i-can-get and he-can-get.
In the completely admissible form of search, i-can-get and he-can-get are initialized to minus infinity, and as the search progresses, the values of i-can-get and he-can-get gradually increase. The true value of the search is always somewhere between i-can-get and the negative of he-can-get. If you have a good a priori estimate of the final value, you can initialize i-can-get and he-can-get to values slightly less than your estimate. This permits cutoffs which would otherwise not occur in branches before the correct line of play is identified.
The hazard of presetting the search parameters is that if the actual value of the search is not inside the initial bounds, you will complete the search with no useful information except that the value is outside the initial bounds. In most Go problems, it isn't useful to make any move in a lost position, so initializing i-can-get to something between a seki and a loss will not lose any information you really need; Example 6 shows that presetting reduces the cost of search by almost 20%.
or click here to see an ascii version
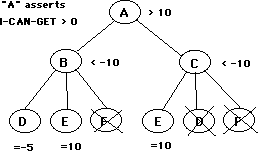
Summary: Suppose the value of B is a loss. If the value of the overall problem is believed to be a win, or if B's owner is only interested in pursuing the problem if it leads to at least a seki, then B's initial i-can-get parameter can be 0, the value of a seki. This permits E to trigger a cutoff to eliminate evaluation of F.
Another standard technique to improve alpha-beta's initial ordering is known as the killer heuristic. Simply stated, moves which have proven to be "good" in "similar" situations are promoted in the ordering among siblings, based on the hope that the killer move will be more effective in the current situation.
Deciding what is similar, and remembering which moves were useful in those circumstances, is an open problem. As I implement it, similar means at the same search depth and good means good enough to cause an alpha-beta cutoff.
For each search depth, I maintain a list of killer biases, such that the sum of all biases is zero. If the current move causes an alpha-beta cutoff, I award it a +1 bias, and redistribute a -1 bias among the other alternatives which were actually evaluated. This tends to reward the good moves and punish the bad moves, but isn't tied exclusively to any situation.
When looking for a killer move to try, I look for for a move at the current search depth with a high enough "killer" bias. Killer biases which are not powerful enough to catapult some sibling to the front, are used to more subtly weight the ordering among siblings.
In effect, this implementation of the killer heuristic promotes one of several siblings, based on experience with positions which are "cousins" in the search tree. Example 7 shows that the killer heuristic reduces the search by a small but significant factor.
or click here to see an ascii version
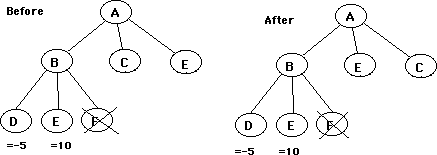
Summary: If node E (child of B) caused an alpha cutoff, so that f did not have to be evaluated, promote E (child of C) ahead of d and f, in the hope that it will also cause a cutoff there.
A second adaptive tree ordering technique I use is a dynamic reordering based on the go proverb my key point is my enemy's key point. If the response to the first sibling causes a cutoff, then promote that move among the remaining siblings.
or click here to see an ascii version
Summary: The preliminary ordering of children of A is B C E, after evaluating B, and discovering that E is the principle variation, promote E to before C among the remaining children of A.
Note that in this case, in example 8, adding sibling promotion actually makes the search examine slightly more nodes. This is unfortunate but not surprising - in general any of these "optimizations" can have the the opposite effect in any particular instance.
In Go, the same positions tend to arise over and over in the search tree. For example, if the sequence (black)A (white)B (black)C occurs, the sequence (black)C (white)B black(A) is also quite likely to occur. Because such repeated positions are so common, a large saving can be achieved by caching and reusing results. Example 5 shows the effect of caching results.
This is simple enough conceptually, but the presence of other forms of tree pruning complicates matters. In the figure 4, the sequence to E caused a cutoff and node f was not evaluated at all, therefore the value for node B is not exact; If f had been evaluated, it might have been even more valuable than E which would change the value of B. The value of B in figure 4 is a lower bound on its true value.
Consider the value of A if B is the best variation: it must be an upper bound on the true value of A. In the direct line of the search, with only alpha-beta pruning in effect, whether a result is an exact value, an upper bound, or a lower bound does not matter. Lower bound values are negated and passed up the tree as upper bounds, which will always be ignored in favor of the value of some previously encountered position. In effect, with alpha-beta pruning, only the exact values are remembered, and all the inexact values are discarded.
However, when a cached value is retrieved, it is vital to remember its type and treat it correctly. Exact values are easy; just use them in place of performing the search locally. Lower bounds, if they are high enough to cause a cutoff, can do so, but otherwise the search should be performed anyway, perhaps with the lower bound as alpha-beta bound. Upper bounds, if they are not high enough to become a new principle variation, need not be investigated, but otherwise the search should be performed anyway.
Various other pruning techniques which will be presented later will also affect (and complicate) the logic of reusing cached results; and the possibility of performing iterative searches, using the cached results of previous iterations, introduces additional complications. I'll note these as I go along.
In practice, caching results is complementary to alpha-beta; If alpha-beta pruning is working well, few repetitive positions are encountered. If alpha-beta is not working well, many repetitive positions are encountered, and caching results will help a lot. Example 3 provides evidence of this; alpha-beta with bad prior ordering , plus caching, is nearly as effective as example 4, alpha-beta with a good prior ordering.
Caching results is also an enabling technique for iterative searches; for example, one might consider a "quick search" with severely restricted width and depth, followed by a wider, deeper search to confirm the preliminary result. Note that the value of iterative searches is not in the work saved by caching previous results, but in ordering the alternatives better the second time around.
If iterative searches (presumably, with with greater depth limits) are to be performed, then it is important to distinguish the value of "depth limited" nodes from the value of nodes that are terminal for some other reason. This introduces three new types of terminals: depth-limited equivalent to exact, estimated lower bound equivalent to lower-bound, and estimated upper-bound equivalent to upper-bound. In the initial search, these three value types are equivalent to the original three, but in iterated searches, the three new types are only estimates, useful for ordering the tree, but not for causing cutoffs. In practice, before each search, I change cached results with the "estimated" value types to just estimate.
Summary: When caching results, it's necessary to distinguish at least seven qualitatively different types of cached values:
All the remaining techniques are inadmissible, because they may change the result of the search. You could get the wrong answer, and not know it. Accordingly, one should use these techniques gingerly.
Forward pruning is when you eliminate whole branches of the tree without evaluation. The most reliable way to do this is to eliminate moves based on very specific knowledge about the game. The least reliable is to simply remove branches based on width, depth, or time constraints.
Do not eliminate all self-atari moves, only those that won't ever be useful moves. I always allow self-atari for single stones. For larger groups, allow self-atari moves only under the following conditions:
Principally, these are snap backs, in which you capture one stone and are then recaptured, and mercy killings in which you capture a group that is not causing an immediate threat and cannot escape. In a race to capture, it frequently occurs that small groups are cut off from all hope of support, but left on the board. Just as it is not useful for the owner to try to rescue them, it is not useful for the opponent to finish them off.
Equivalent moves are hard to find. The largest class of equivalent moves I've been able to identify is "approach" moves which fill outside liberties.
Example 9 shows the benefit when these forward pruning techniques are added to the search.
Stopping the search when the guaranteed outcome is good enough can eliminate a lot of useless searching for an even better move; refer to example 10. Of course, as a consequence of not looking, a better move may not be found, if it exists. The main use of this strategy is to call any winning move good enough; and therefore not look for the best winning move.
If small differences in the value of terminal nodes are ignored, better alpha-beta cutoffs can result. For example, if winning in 3 moves or winning in 4 moves are considered to be the same, then whichever is found first will be the principle variation, and whichever is found second will cause an alpha-beta cutoff. If they are considered to be different, and if the better move is found first, the less preferred move won't cause a cutoff, and more alternatives will have to be examined.
or click here to see an ascii version
If E and G are have the same value, or G is slightly greater, then h and i need never be evaluated (because A will always choose B over C). If E is slightly greater than G, then h and i will be evaluated. So by eliminating "insignificant" differences between valuations, better cutoffs are produced. Example 11 shows this effect.
It is always tempting to simply stop looking after a certain number of alternatives have been examined; for example, after a "width limit" is reached. The problem with such arbitrary limitations is that they don't consider the consequences of not finding the better move. Frustration cutoffs occur when looking for a better move, which if found, would cause both players to avoid this line of play. Example 12 shows the effect of adding frustration cutoffs to all the other methods.
or click here to see an ascii version
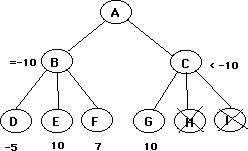
Suppose B provides a guaranteed value of "x", and B's owner is in the process of evaluating J, K, L, and M, looking for a better alternative to B. If he finds it, then it will cause an alpha-beta cutoff, and node G will be avoided. If J, K, L, and M are all inferior to B, then G will cause an alpha-beta cutoff, and node C will be avoided. What's the point in evaluating J,K,L, and M at all? In other words, under what circumstances could the principal variation shift from B to C? If any of the children of C are not improvements on B, then B will always be preferred. If all of the children of C are improvements on B, then C will be the new principle variation. By calling off the search after evaluating only some of J K L M, B's owner causes everything below C to be discarded, at the cost of possibly missing some improvement on B that is inherent in all children of C. In effect, it is reasonable to abandon the search when J, K, L, and M appear to offer no improvement. It only causes actual harm if there actually is a better move among the successors of G, and among the successors of all of the other successors of C.
Consider this extremely simple problem, with black to move:
or click here to see an ascii version
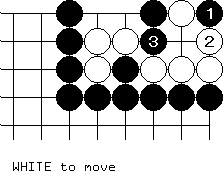
There are only six places to play. The correct line of play is this; after which white has no moves that are not self-atari:
or click here to see an ascii version
To evaluate the full search tree for this problem, to the point where white is actually captured or has formed a shape that is statically recognized as dead, requires examining more than 50,000 positions! The bulk of these positions involve "clearly useless" lines of play in which the white group at the left is captured, and white is attempting to recapture the capturing stones. In this position, it's a hopeless proposition.
Reading these results:
Time is the time required to solve the problem
Nodes is the number of nonterminal nodes with children
Evals is the number of positions statically evaluated
Seen is total positions seen, including cached positions which didn't
require evaluation.
#1: Full tree, no cutoffs at all. Time: 1 hour 49 minutes 56 seconds, 22605 Nodes, 51421 Evals
#2: Alpha-Beta Only (reverse ordering) Time: 27 minutes 50 seconds, 4941 Nodes, 11835 Evals
#3: Alpha-Beta (reverse ordering), Result Caching Time: 4 minutes 55 seconds, 680 Nodes, 1477 Evals
#4: Alpha-Beta Only (good ordering) Time: 2 minutes 25 seconds, 198 Nodes, 580 Evals
#5: Alpha-Beta (good ordering), Result Caching Time: 57 seconds, 141 Nodes, 399 Evals, 506 Seen,
#6: Alpha-Beta + Result Caching, Preset i-can-get Time: 53 seconds, 118 Nodes, 330 Evals, 411 Seen,
#7: Alpha-Beta + Result Caching, Preset i-can-get, killer heuristic Time: 54 seconds, 121 Nodes, 327 Evals, 364 Seen,
#8: Alpha-Beta + Result Caching, Preset i-can-get, killer heuristic, sibling promotion Time: 46 seconds, 124 Nodes, 341 Evals, 371 Seen
#9: Alpha-Beta + Result Caching, Preset i-can-get, killer heuristic, sibling promotion + Forward pruning of self-atari, useless capturing moves, equivalent moves Time: 37 seconds, 91 Nodes, 275 Evals, 305 Seen
#10: Alpha-Beta + Result Caching, Preset i-can-get, killer heuristic, sibling promotion + Forward pruning of self-atari, useless capturing moves, equivalent moves + good-enough cutoffs Time: 38 seconds, 82 Nodes, 251 Evals, 274 Seen
#11: Alpha-Beta + Result Caching, Preset i-can-get, killer heuristic, sibling promotion + Forward pruning of self-atari, useless capturing moves, equivalent moves + good-enough + terminals made equal Time: 30 seconds, 77 Nodes, 239 Evals, 259 Seen
#12: Alpha-Beta + Result Caching, Preset i-can-get, killer heuristic, sibling promotion + Forward pruning of self-atari, useless capturing moves, equivalent moves + good-enough + terminal-are-equal + frustration cutoffs Time: 33 seconds, 75 Nodes, 238 Evals, 256 Seen
figure 1
A
/ \
B C
/ || \ //| \
D E F G h i
Back
figure 2
A
/ \
B C
/ || \ //| \
D E f G h i
Back
figure 3
A
/ \
B C
/ || \ / | \
D E f E d f
Back
figure 4
Before: A
/ | \
B C E
/ || \
D E f
After: A
/ | \
B E C
/ || \
D E f
Back
figure 5
A
/ \
B C
/ || \ //| \
D E F G h i
Back
figure 6
A
// \
B C
/ || \ / \ \
D E F G H I
|\ \ \
J K L M
Back
figure 7
- - - - - - - - -
x . . x o . |
x o o . . . |
x o x o o o |
x x x x x x |
|
Black (x) to move
Back
figure 8
- - - - - - - - -
x . . x o 1 |
x o o 3 . 2 |
x o x o o o |
x x x x x x |
|
The correct line of play
Back